Project Overview
Spam messages pose significant security risks and annoyances in mobile communication. This project addresses the challenge of accurately detecting spam by implementing advanced Natural Language Processing (NLP) techniques. By utilizing the SMS Spam Collection dataset, the project develops hybrid deep learning models that combine Convolutional Neural Networks (CNN) for local feature extraction and Long Short-Term Memory (LSTM) for capturing sequential dependencies in text. The primary goal is to provide a robust classification system that maintains accuracy despite the imbalanced nature of spam data through techniques like class weighting and text augmentation.
System Architecture
Text Tokenizer
Converts raw SMS text into numerical sequences with a 10,000-word vocabulary and OOV handling.
Embedding Layer
Transforms high-dimensional word indices into dense 64-dimensional vectors for semantic representation.
CNN Layer
Uses 1D convolution with 64 filters to extract local spatial patterns and features from text sequences.
LSTM/BiLSTM Layer
Processes sequential data to capture long-term dependencies, with Bidirectional support for enhanced context understanding.
Dense Output Layer
Uses a Sigmoid activation function to provide a final probability score for binary spam classification.
Key Features
Hybrid Model Design
Combines CNN and LSTM layers to leverage both spatial and temporal text features.
Class Weighting
Implements balanced class weights to mitigate the impact of imbalanced "ham" versus "spam" datasets.
Text Augmentation
Uses NLTK WordNet for synonym replacement, increasing the diversity of the training data.
Automated Tuning
Integrates Keras Tuner with Grid Search to systematically find the optimal model hyperparameters.
Early Stopping
Employs monitoring to prevent overfitting by halting training when validation loss stops improving.
System Flow
Data Preparation
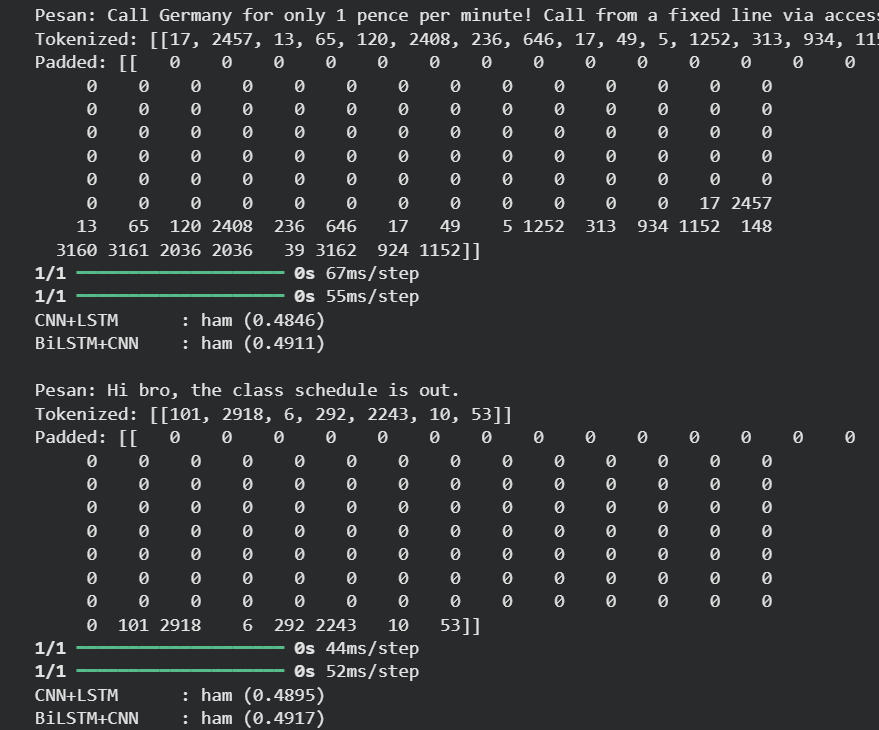
SMS data is downloaded, labeled, and converted into padded numerical sequences of 120 tokens.
Model Construction
Hybrid architectures (CNN+LSTM or BiLSTM+CNN) are built with dropout layers for regularization.
Training Process
Models are trained using binary cross-entropy loss and Adam optimizer with class weights enabled.
Evaluation & Tuning
Performance is assessed via confusion matrices and tuned through automated Grid Search or manual iterations.
Inference Phase
New messages are tokenized and processed by the trained model to predict spam probability.
Project Outcome
The project successfully developed a good accuracy SMS classifier, with both CNN+LSTM and BiLSTM+CNN architectures achieving strong performance on test data. Through automated hyperparameter tuning and text augmentation, the system demonstrated good precision in detecting spam while maintaining low false-positive rates for legitimate messages. The final model is capable of real-time spam detection for unseen text inputs.
Screenshots